Background
In the realm of data visualization, the classical scatter plot has long been a staple for exploring bivariate relationships. However, as datasets grow larger and more complex, traditional scatter plots can become cluttered and less informative. Privacy concerns may also limit the ability to plot raw data, and simple bivariate plots often fail to reveal causal relationships. This is where binscatter, or binned scatter plots, come into play.
Binscatter offers a cleaner, more interpretable way to visualize the relationship between two variables, especially when dealing with large datasets. By aggregating data points into bins and plotting the average outcome within each bin, binscatter simplifies the visualization, making it easier to discern patterns and trends. It’s particularly useful for:
- Intuitive visualization for large datasets by grouping data into bins.
- Highlighting trends and relationship between variables effectively.
- Extending these ideas to control for covariates.
In this article, I will introduce binscatter, explore its mathematical foundation, and demonstrate its utility with an example in R.
Notation
To formalize binscatter, let’s define the following:
 : The independent/predictor variable.
: The independent/predictor variable. : The dependent/outcome/response variable.
: The dependent/outcome/response variable. : The number of observations in the dataset.
: The number of observations in the dataset. : The number of bins into which is divided.
: The number of bins into which is divided. : The mean of for observations falling in the
: The mean of for observations falling in the  -th bin of . Similarly for
-th bin of . Similarly for  .
. : The observations falling in the -th bin.
: The observations falling in the -th bin. : The covariate to be controlled. This can be a vector too.
: The covariate to be controlled. This can be a vector too.
Diving Deeper
Formal Definition
A binscatter plot is constructed by partitioning the range of the independent variable into a fixed number of bins,  typically using empirical quantiles. This ensures each bin is of roughly the same size. Within each bin, the average value of the dependent variable is calculated. These averages are then plotted against the midpoint of each bin,
typically using empirical quantiles. This ensures each bin is of roughly the same size. Within each bin, the average value of the dependent variable is calculated. These averages are then plotted against the midpoint of each bin,  , resulting in a series of points that represent an estimate of conditional mean of given ,
, resulting in a series of points that represent an estimate of conditional mean of given , ![E[Y|X]](https://yasenov.com/wp-content/ql-cache/quicklatex.com-2b13d4f96e184a773763ac00c8392aea_l3.png "Rendered by QuickLaTeX.com") .
.
In technical jargon binscatter provides a nonparametric estimate of the conditional mean function, offering a visual summary of the relationship between the two variables. The resulting graph allows assessment of linearity, monotonicity, convexity, etc.
Here is the step-by-step recipe for construcing a binscatter plot.
Algorithm:
- Bin construction: Divide the range of into equal-width bins, or use quantile-based bins for equal sample sizes within bins.
- For example, with
 , the observations in
, the observations in  would be those between the minimimum value of and that of its 10th percentile.
would be those between the minimimum value of and that of its 10th percentile.
- For example, with
- Mean calculation: Compute the mean of within each bin:
where![\[\bar{Y}_k= \frac{1}{|B_k|} \sum_{i \in B_k} Y_i,\]](https://yasenov.com/wp-content/ql-cache/quicklatex.com-9e196f198e4afcd7294c525daec41bae_l3.png "Rendered by QuickLaTeX.com")
 is the number of observations in bin .
is the number of observations in bin . - Plotting: Plot against the midpoints of each bin, .
Software Package: binsreg.
Quite simple, right? Let’s explore certain useful extensions of this idea.
Adjusting for Covariates: The Wrong Way
In many applications, it is essential to control for additional covariates to isolate the relationship between the primary variables of interest. The object of interest then becomes the conditional mean ![E[Y|W,X]](https://yasenov.com/wp-content/ql-cache/quicklatex.com-0071c5fba8f413d420e2aeef8474a96c_l3.png "Rendered by QuickLaTeX.com") . An example would be focusing on the relationship between income () and education level () when controling for parental education ().
. An example would be focusing on the relationship between income () and education level () when controling for parental education ().
A common but flawed approach to incorporating covariates in binscatter is residualized binscatter. This method involves first regressing separately both and on the covariates to obtain residuals  and
and  , and then applying the binscatter method to these residuals:
, and then applying the binscatter method to these residuals:
![\[\bar{\hat{u}}_{Y,k} = \frac{1}{|B_k|} \sum_{i \in B_k} \hat{u}_{X,i}.\]](https://yasenov.com/wp-content/ql-cache/quicklatex.com-55aa8c7dd1ceacbf531f47d20c56c4fa_l3.png "Rendered by QuickLaTeX.com")
While this approach is motivated by the Frisch-Waugh-Lovell theorem in linear regression, it can lead to incorrect conclusions in more general settings. The residualized binscatter may not accurately reflect the true conditional mean function, especially if the underlying relationship is nonlinear. Therefore, it is generally not recommended for empirical work.
Adjusting for Covariates: The Right Way
Instead, this should be done using a semi-parametric partially linear regression model. This is achieved by modeling the conditional mean function as
![\[Y = \mu_0(X) + W \gamma_0 + \varepsilon,\]](https://yasenov.com/wp-content/ql-cache/quicklatex.com-ed4df2dfadd747b43fddd41924d39bd5_l3.png "Rendered by QuickLaTeX.com")
where  captures the main effect of , and
captures the main effect of , and  adjusts for the influence of additional covariates. Rather than residualizing, we estimate using the least-squares approach:
adjusts for the influence of additional covariates. Rather than residualizing, we estimate using the least-squares approach:
![\[(\hat{\beta}, \hat{\gamma}) = \arg\min_{\beta, \gamma} \sum (Y- b(X)' \beta - W' \gamma)^2,\]](https://yasenov.com/wp-content/ql-cache/quicklatex.com-74d05de0ee117ddab4f739894cd6e16b_l3.png "Rendered by QuickLaTeX.com")
where  represents the binning basis functions. The final binscatter plot displays the estimated conditional mean function
represents the binning basis functions. The final binscatter plot displays the estimated conditional mean function
![\[\hat{\mu}(X_k) = b(X_k)' \hat{\beta}\]](https://yasenov.com/wp-content/ql-cache/quicklatex.com-ac34ae8894b5ea1e6ac7d4e5bd3b3646_l3.png "Rendered by QuickLaTeX.com")
against , ensuring a correct visualization of the relationship between and after accounting for covariates .
Practical Considerations
A key decision is the choice of the number of bins . Too few bins can oversmooth the data, masking important features, while too many bins can lead to undersmoothing, resulting in a noisy and less interpretable plot. An optimal choice of balances bias and variance, often determined using data-driven methods. To address this, Cattaneo et al. (2024) propose an adaptive, Integrated Mean Squared Error (IMSE)-optimal choice of for which get a plug-in formula.
Thoughtful data scientist always have variance in their mind. If, for instance, we see some linear relationship between and , how can we determine whether it is statistically significant? Quantifying the uncertainty around binscatter estimates is crucial. The authors also discuss constructing confidence bands, which can be added to the plot to visually represent estimation uncertainty, enhancing both interpretability and reliability.
An Example
As an example let’s examine the relationship between the variables Sepal.Length and Petal.Length in the popular iris dataset. We will use a fixed number of ten bins. Alternatively, the package binsreg will automatically calculate the optimal .
rm(list=ls())
library(ggplot2)
library(dplyr)
library(binsreg)
data(iris)
bins <- 10
iris_binned <- iris %>%
mutate(bin = cut(Sepal.Length, breaks = bins, include.lowest = TRUE)) %>%
group_by(bin) %>%
summarize(
bin_mid = mean(as.numeric(as.character(bin))),
mean_petal_length = mean(Petal.Length)
)
iris_raw <- iris %>%
mutate(panel = "1. Raw Scatter Plot")
iris_binned <- iris_binned %>%
mutate(panel = "2. Binned Scatter Plot")We have split the data into ten bins, now let’s plot it.
plot_data <- bind_rows(
iris_raw %>% rename(x = Sepal.Length, y = Petal.Length),
iris_binned %>% rename(x = bin_mid, y = mean_petal_length)
)
ggplot(plot_data, aes(x = x, y = y)) +
geom_point() +
facet_wrap(~ panel, scales = "free_x", ncol = 2) +
labs(title = "Comparison of Raw and Binned Scatter Plots",
x = "Sepal Length",
y = "Petal Length") +
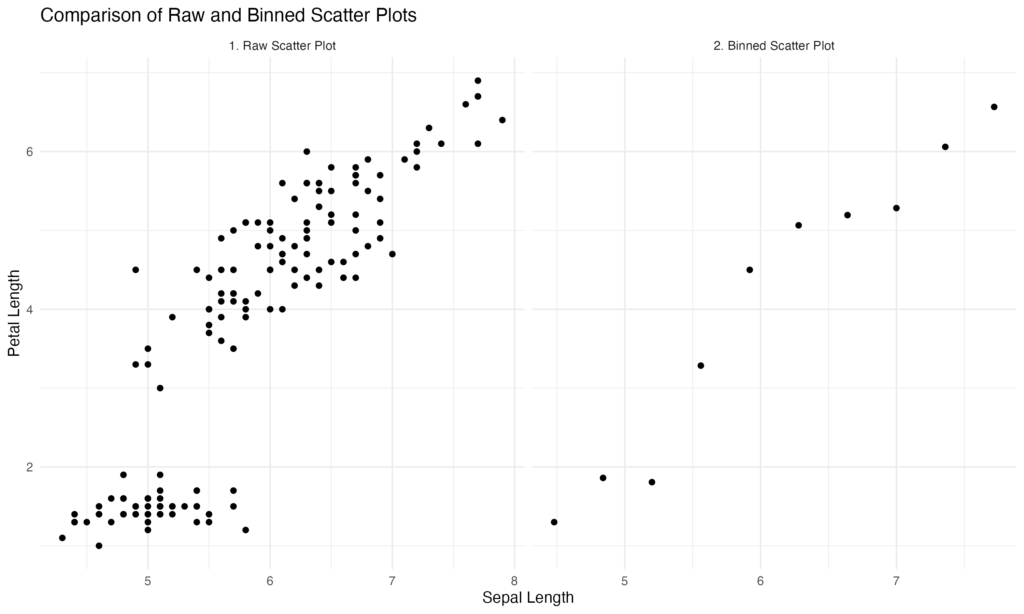
theme_minimal()Here is the resulting image. The left scatter plot displays the raw data and the right one shows the binscatter. Binscatter removes some of the clutter and highlights the linear relationship more directly.
You can download the code from this GitHub repo.
Bottom Line
- Binscatter simplifies scatterplots by aggregating data into bins and plotting means.
- It is a powerful tool for visualizing relationships in large or noisy datasets.
- Conditional and residualized binscatter extend its utility to controlling for covariates.
- While intuitive, binscatter is sensitive to binning choices and may obscure nuances.
Where to Learn More
Both papers in References section below are relatively accessible and will answer your questions. Start with Starr and Goldfarb (2020).
References
Cattaneo, M. D., Crump, R. K., Farrell, M. H., & Feng, Y. (2024). On Binscatter Regressions. American Economic Review, 111(3), 718–748.
Starr, E., & Goldfarb, B. (2020). Binned scatterplots: A simple tool to make research easier and better. Strategic Management Journal, 41(12), 2261-2274.
Leave a Reply