Background
Statistical modeling is among the most exciting elements of working with data. When mentoring junior data scientists, I never fail to see the spark in their eyes when our projects have overcome the data gathering and cleaning stages and have reached that precious Rubicon.
A major goal in the craft of statistical modeling is extracting the most information from the data at hand. Statisticians and econometricians call this efficiency or precision. In simple terms, this means achieving the lowest possible variance from a class of available estimators. As an example, imagine two findings—both centered at 3% (e.g., the treatment effect of an intervention of interest)—but one with a 95% confidence interval of [2%, 4%], and the other with [-7%, 13%]. The former is clearly more informative and useful than the latter.
In a series of four articles, I will dive deeper into the topic of efficiency with a varying degree of detail and complexity. As a first step in this exploration, I want to demystify the distinction between the three classes of statistcal models: parametric, semiparametric, and nonparametric. The goal of this article is to explore in depth the concepts of parameterizing a model and the distinctions between these three groups. Let’s get started!
Diving Deeper
Parametric Models
Parametric models impose strong assumptions about the underlying data-generating process, making them less flexible but highly interpretable and data-efficient. They require fewer data points to estimate the target accurately compared to semiparametric or nonparametric models. Consequently, they are often the default choice in practice.
A classic example is density estimation. Suppose you observe that your data appears symmetric around its mean. You might assume the data follows a normal (Gaussian) distribution. In this case, specifying the mean  and variance
and variance  fully characterizes the distribution, allowing you to estimate the density parametrically. And then, you can make all kinds of calculations related to your variable, such as what is the probability that it will take values greater than
fully characterizes the distribution, allowing you to estimate the density parametrically. And then, you can make all kinds of calculations related to your variable, such as what is the probability that it will take values greater than  .
.
Formally, a parametric model describes the data-generating process entirely using a finite-dimensional parameter vector. As yet another example, in the omnipresent linear model:
![\[Y = X\beta + \epsilon,\]](https://yasenov.com/wp-content/ql-cache/quicklatex.com-4e5cfcb16a02c7b334b5cc311a71de41_l3.png "Rendered by QuickLaTeX.com")
the parameter  specifies the entire relationship between
specifies the entire relationship between  and
and  . This imposes a strong assumption: the relationship is linear, meaning a unit change in consistently results in a change in , regardless of ‘s magnitude (small or large). While convenient, this assumption may not hold in all practical scenarios, as real-world relationships often are complex and deviate from linearity.
. This imposes a strong assumption: the relationship is linear, meaning a unit change in consistently results in a change in , regardless of ‘s magnitude (small or large). While convenient, this assumption may not hold in all practical scenarios, as real-world relationships often are complex and deviate from linearity.
Semiparametric Models
Semiparametric models combine the structure of parametric models with the flexibility of nonparametric methods. They specify certain aspects of the data-generating process parametrically while leaving other aspects unspecified or modeled flexibly.
Consider the partially linear model:
![\[Y = X \beta + g(Z) + \epsilon,\]](https://yasenov.com/wp-content/ql-cache/quicklatex.com-d2799a7e7df05dbdb63f2c438318ab10_l3.png "Rendered by QuickLaTeX.com")
where is a parametric component describing the linear effect of , while  is an unknown and potentially complex function capturing the nonparametric effect of a covariate matrix
is an unknown and potentially complex function capturing the nonparametric effect of a covariate matrix  . Here, the model imposes linearity on ‘s effect but allows ‘s effect to be fully flexible.
. Here, the model imposes linearity on ‘s effect but allows ‘s effect to be fully flexible.
Semiparametric models are highly versatile, balancing the interpretability of parametric models with the adaptability of nonparametric ones. However, estimating efficiently while accounting for the unknown poses challenges, often requiring further assumptions.
In practice, semiparametric models play a crucial role in causal inference, particularly when working with observational cross-sectional data (see Imbens and Rubin 2015). A common strategy involves estimating propensity scores using parametric models (like logistic regression) and then employing nonparametric techniques such as kernel weighting, matching, or stratification to estimate treatment effects. This hybrid approach helps address confounding while maintaining computational tractability and interpretability.
Nonparametric Models
Nonparametric models make minimal assumptions about the underlying data-generating process, allowing the data to “speak for itself”. Unlike parametric and semiparametric models, these ones do not specify a finite-dimensional parameter vector or impose rigid structural assumptions. This flexibility makes them highly robust to model misspecification but often requires larger datasets to achieve accurate estimates.
Let’s get back to the density estimation example. Histograms are a form of nonparametric models as they do not assume specific underlying functional form. Instead of fitting a parametric distribution (e.g., normal), you might use a kernel density estimator:
![\[\hat{f}(x)=\frac{1}{nh}\sum_i K \left( \frac{x-X_i}{h} \right),\]](https://yasenov.com/wp-content/ql-cache/quicklatex.com-df52ab3519eab0a9acedd51b3efaefa3_l3.png "Rendered by QuickLaTeX.com")
where  is a kernel function, and
is a kernel function, and  is a bandwidth parameter controlling the smoothness of the estimate. А kernel function assigns varying weight to observations around a data point. They are non-negative, symmetric around zero, and sum to one. Commonly employed kernel functions include:
is a bandwidth parameter controlling the smoothness of the estimate. А kernel function assigns varying weight to observations around a data point. They are non-negative, symmetric around zero, and sum to one. Commonly employed kernel functions include:
- Gaussian
 ,
, - Epanechnikov
 ,
, - Rectangular:

This approach does not rely on assumptions about the data’s shape, allowing it to adapt to various distributions.
Nonparametric regression provides another illustration. In it, the relationship between and is modeled as:
![\[Y=m(X)+\epsilon,\]](https://yasenov.com/wp-content/ql-cache/quicklatex.com-4a41ae778218155c083cd8c5a179b359_l3.png "Rendered by QuickLaTeX.com")
where  is an unknown function estimated directly from the data using methods like local polynomial regression, splines. Unlike the linearity assumption in parametric models, nonparametric regression allows to capture complex, nonlinear relationships. A commonly used variant of this is LOESS regression often overlayed in bivariate scatterplots.
is an unknown function estimated directly from the data using methods like local polynomial regression, splines. Unlike the linearity assumption in parametric models, nonparametric regression allows to capture complex, nonlinear relationships. A commonly used variant of this is LOESS regression often overlayed in bivariate scatterplots.
Many popular machine learning (ML) methods are also nonparametric. In this context it is important to distinguis between parameters which impose assumptions on the data and hyperparameters which serve to tune the algorithm. Tree-based techniques exemplify the nonparametric nature of ML: gradient boosting machines, random forests, and individual decision trees can all grow more complex as they encounter more data, creating flexible models that capture intricate patterns. Think even of unsupervised clustering models including k-means and hierarchical clustering.
While nonparametric models are powerful, their flexibility comes at a cost: they can overfit small datasets and often require careful tuning (e.g., choosing the kernel bandwidth) to balance bias and variance. Nonetheless, they are invaluable for exploratory analysis and applications where minimal assumptions are desired.
Did I also mention the curse of dimensionality?! You will quickly fall into its trap with even moderate number of variables. Yes, there is just so much you can do without adding some structure to your models.
An Example
We illustrate the distinctions between parametric, semiparametric, and nonparametric models using a toy example. We generate 1,000 observations of
![\[Y=sin(X)+\epsilon,\]](https://yasenov.com/wp-content/ql-cache/quicklatex.com-4bf72a85bdd03f3fea01928845986182_l3.png "Rendered by QuickLaTeX.com")
where is uniformly distributed and  is normally distributed noise. We then model the relationship between Y and X using three approaches. A parametric model, such as linear regression (although it could also be quadratic or a higher order polynomial), provides a simple, interpretable approximation but may miss crucial aspects of the true relationship. A “semiparametric” model, like piecewise linear regression, offers greater flexibility by allowing for changes in slope, capturing some curvature while maintaining a degree of interpretability. (One can cast this piecewise linear model as a parametric one, but for simplicity’s sake let’s go with this uncommon and imprecise definition of semiparametric.) Finally, a nonparametric model, such as LOESS, provides the most flexible representation, closely following the underlying sinusoidal pattern but potentially leading to overfitting.
is normally distributed noise. We then model the relationship between Y and X using three approaches. A parametric model, such as linear regression (although it could also be quadratic or a higher order polynomial), provides a simple, interpretable approximation but may miss crucial aspects of the true relationship. A “semiparametric” model, like piecewise linear regression, offers greater flexibility by allowing for changes in slope, capturing some curvature while maintaining a degree of interpretability. (One can cast this piecewise linear model as a parametric one, but for simplicity’s sake let’s go with this uncommon and imprecise definition of semiparametric.) Finally, a nonparametric model, such as LOESS, provides the most flexible representation, closely following the underlying sinusoidal pattern but potentially leading to overfitting.
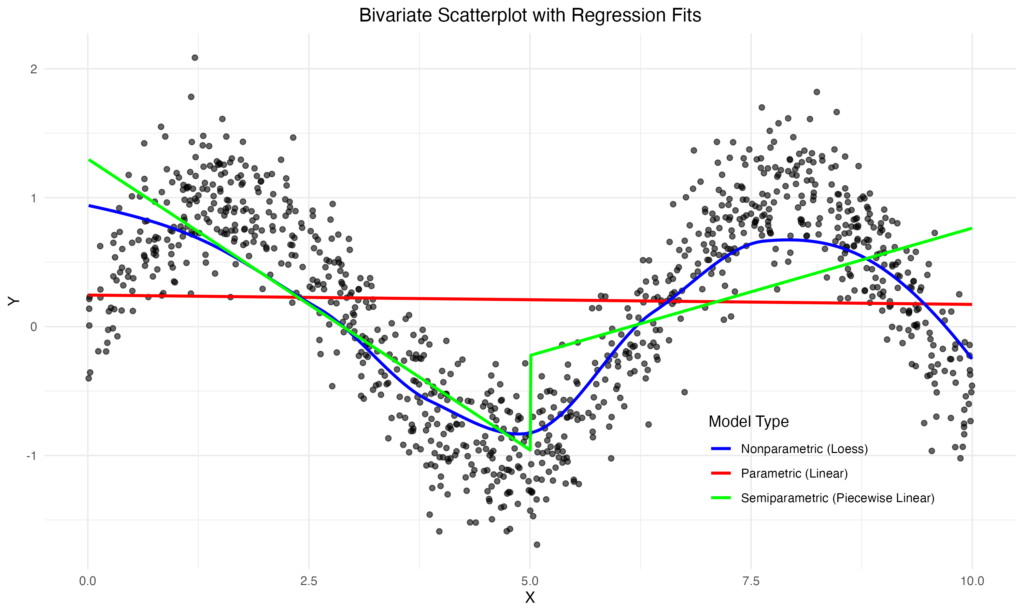
You should not be surprised. This example demonstrates how the choice of model class significantly impacts the flexibility and interpretability of the fitted relationship. Do not take this example too seriously, it merely serves to illustrate the varying degree of complexity of statistical models.
You can download the code to reproduce the figure from this GitHub repo.
Bottom Line
- Parametric models impose the strongest assumptions and require the least amount of data. These are most models employed in practice. Think of linear regression.
- Semiparametric models strike balance between flexibility and interpretation while allowing for flexible relationships in the data. Think of (non-Augmented) Inverse Propensity Score Weighting.
- Nonparametric models are flexible and data-hungry. They allow for flexible associations between your variables. Think of a histrogram or kernel density.
References
Imbens, G. W., & Rubin, D. B. (2015). Causal inference in statistics, social, and biomedical sciences. Cambridge university press.
Leave a Reply